How to Spot a Tipster's Fake Betting History
Posted 31st March 2017
In my second book How to Find a Black Cat in a Coal Cellar: The Truth About Sports Tipsters I discussed at length various means we can use to test the profitability, validity and reliability of a sports-tipster's betting history, including the t-test, website domain checks and the presence or absence of independent verification. I've also previously written here how we can use the closing line to determine if a tipster is just being lucky or whether he's demonstrating something more. Today I want to share with you a neat little trick, or rather statistical technique, which exploits human fallibility, that can be used to test whether a tipping history has arisen naturally or whether it has been artificially put together.
Human beings are rather poor judges of randomness. We suffer a cognitive bias known as the clustering illusion, with a tendency to erroneously consider inevitable runs or clusters arising in random distributions to be meaningful. By way of example, consider the following series of wins (W) and losses (L). One series is a random pattern of results from the world of sport whilst the other one is a fake; which is which?
1) LWLLLLLLWLWLWLLLWWLLWLWWLLWWWWWW
2) WLLWWLLLWLWLWWLWLLWLLWWWLLWLWLWW
Did you believe that the long sequences of the same result in series 1) look manufactured? Did you think the shorter sequences in 2) make that one look more random? If so, then you've got the two the wrong way around. In fact, series 1) represents the 1973 to 2004 results for Cambridge University in the Boat Race. Series 2 is just made up. It might look more random on account of its shorter sequences of wins and losses, but in fact it was artificially constructed to be so. When asked to actually create random binary sequences most of us will switch from W to L or vice versa if they feel that one of them is happening too often. Long sequences of the same outcome are perceived as being non-random.
In fact there is a way to test how random a sequence of binary data is. It's the Wald—Wolfowitz runs test for randomness. Named after Abraham Wald (the statistician who discovered survivorship bias) and Jacob Wolfowitz, this test determines whether a binary data sequence, for example wins and losses, arises from a random process. The test was famously used by Thomas Gilovich, Robert Vallone and Amos Tversky when investigating the misperception of random sequences in basketball shooting, the so-called hot hand fallacy.
Regardless of any influence arising from a tipster's skill which would increase his win rate, streaks of wins and losses will still reflect the underlying random noise in his betting history, since each sequential bet is independent of the previous. A tipster with a 75% strike rate from even-money propositions, for example, would be incredibly skilled with three times as many winners as losers, but the sequence distribution would nonetheless still be random.
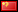
The Wald—Wolfowitz runs test works by comparing the number of observed runs (or streaks) of wins and losses to the number we would expect from a random series of the same number of wins and losses. Imagine a series of 10 wins and 20 losses. If the sequence was 10 wins followed by 10 losses this would imply just 2 runs. By contrast, the number of expected runs is given by the following statistic:
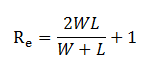
In this example, the expected number of runs is 11. Clearly this is far more than the 2 runs observed, from which we would likely conclude that the sequence is very probably non-random, or in other words, artificially constructed.
We can quantify the probability that a series of wins and losses is random. First we just need to know the standard deviation in the distribution of the number of possible runs. This is given by:
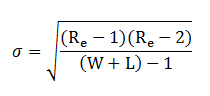
Then we calculate the test statistic (Z), defined by:
where Ro is the observed number of runs. Finally we convert this into a probability (the p-value) that the difference between the observed and expected number of runs could have arisen by chance. In Excel this can be performed using the NORMSDIST function. I have built a simple Wald—Wolfowitz runs test calculator for use in Excel which will perform all the calculations automatically. The smaller the p-value, the greater the likelihood that the hypothesis of randomness and statistical independence of the win-loss sequence may be rejected. Typically this happens at p-value = 0.05 or 5% (Z = 1.96) or sometimes 0.01 or 1% (Z = 2.58).
A successful runs test rests on the assumption that the probability of each bet outcome, that is to say the betting odds, is the same. Naturally, nearly all tipsters advise a variety of betting prices. However, provided that the range of betting odds is fairly narrow, as is the case for Asian handicappers and point spread bettors, this assumption should not be violated excessively. For cases where the range of odds is much wider, I have also built an alternative Monte Carlo runs calculator that will take into account the different outcome probabilities of each bet. The Monte Carlo method is useful where defining mathematical expectation algorithmically from first principles, as the Wald—Wolfowitz test does, is far too complex. Let's now test our calculators on an example betting history.
AH Betting was an Asian handicap football picks service (with a few additional match odds and total goals tips) that I verified from the 9th September 2009 until the 20th March 2011 through my former monitoring service Sports-Tipsters.co.uk. Odds ranged from 1.62 to 2.4 with an average of 1.94. This verified record closed with a yield of 2.60% from 858 bets. Naturally, given that I received every tip one would hope that the record of wins and losses would be entirely legitimate and pass the Wald—Wolfowitz test. To perform it I first had to remove the 58 handicap draws, being as they are neither wins nor losses. Furthermore, half wins were treated as wins with 1/2 losses as losses, to ensure I had a binary sequence of wins and losses. Sure enough, the test returned a z-score of 0.86 and a p-value of 0.39. Using the Monte Carlo version (1,000-runs) yielded a z-score of 0.88 and a p-value of 0.38, thus confirming the robustness of the Wald—Wolfowitz test for this range of betting odds as well as the fact that the sequence of wins and losses was to all intents and purpose random.
AH Betting's owner, Davy, had come to me with an earlier record dating back to the 26th May 2008 showing a more impressive +14.9% yield from 771 selections. Odds ranged from 1.43 to 2.41 with an average of 1.88. At the time, I never doubted the credibility of the record. Yes, it was very impressive, indeed with just 1-in-a-million probability it could have happened by chance, but why would anyone choose to have their tips verified independently if they had previously been cheating? Again removing the handicap draws (40) the results from the 2 tests were as follows: Wald—Wolfowitz test: z-score = 5.16, p-value = 0.0000002; Monte Carlo test: z score = 5.04, p-value = 0.0000005. Unequivocally, this pre-verification record was not random. In fact it had far too few runs or streaks (279) compared to what would be expected from a properly random sequence containing 455 winners and 276 losers (345). Almost certainly this will have arisen because Davy either gave no thought to what a faked betting record should look like to fool people, or he managed to fool himself in the process of its construction.
The more statistically literate amongst us, including many sports betting tipsters, might believe we won't be so easily fooled by randomness. Really, how hard can it be to build a fake sequence of wins and losses that looks random and passes the test? So I tried myself, by seeing if I could build a randomised binary sequence of 100 theoretical fair coin tosses and running the Wald—Wolfowitz test. Repeating this 10 times, I obtained the following p-values. These are compared to 10 properly randomly generated 100-coin-toss sequences using Excel's random number generator.
| My attempts | Randomly generated |
| 0.01 | 0.31 |
| 0.05 | 0.38 |
| 0.01 | 0.84 |
| 0.01 | 0.54 |
| 0.01 | 0.64 |
| 0.03 | 0.30 |
| 0.16 | 0.01 |
| 0.16 | 0.64 |
| 0.05 | 0.95 |
| 0.03 | 0.92 |
Evidently, even knowing that it's easy to be fooled by randomness did not stop me being fooled by it. In 6 out of my 10 attempts I failed to beat the 5% significance level. Contrast my p-values with those through random generation by Excel. A two-sample t-test on these 2 sets of scores confirms that there is just a 1-in-500 probability that my failure to build properly random sequences happened because of bad luck.
So what of Davy? Well, it turned out that he made quite a name for himself, setting up an "independent" tips verification service (Verifybet) which in retrospect was obviously a means to self-verify his own "work" and pass it off as legitimate, and securing a role as forum moderator and tips surveillance commander-in-chief at the betting forum Betting Advice, which ultimately served as a mechanism for legitimising his attempt at managing a betting fund, Saving on Sports. Indeed, Betting Advice's Surveillance service was shut down on the back of Davy's shenanigans. Just at the time Davy's machinations at Betting Advice were exposed, his betting fund suffered a series of heavy losses, leaving customers out of pocket, some to the tune of tens of thousands of Euro. Saving on Sports was shut down with promises to win the money back for affected clients. It's unclear why the fund failed so spectacularly. We might speculate it was because of irresponsible loss chasing or simply because it represented a Ponzi scheme which run out of new customers to pay for old ones. Since then, it's unclear to what extent, if at all, any affected customers have been compensated. Given Davy's obvious willingness to fake a betting history for financial gain, we can't have much confidence that he gives a damn.
|